RabbitMQ
消息中间件概述
消息队列简介
消息队列(message queue)简称MQ,是一种以“先进先出”的数据结构为基础的消息服务器。
消息:在两个系统要传输的数据
作用:实现消息的传递
数据传输方式为同步传输【作为调用方必须等待被调用方执行完毕以后,才可以继续传递消息】,同步传输存在的弊端:传输效率较低。

消息队列应用场景
主要的作用:
[1]系统解耦
[2]流量消锋
[3]数据分发
系统解耦
系统的耦合性越高,容错性【是指系统在部分组件(一个或多个)发生故障时仍能正常运作的能力】就越低
如下下图所示:

使用消息队列以后,整个下单操作的架构如下图所示:
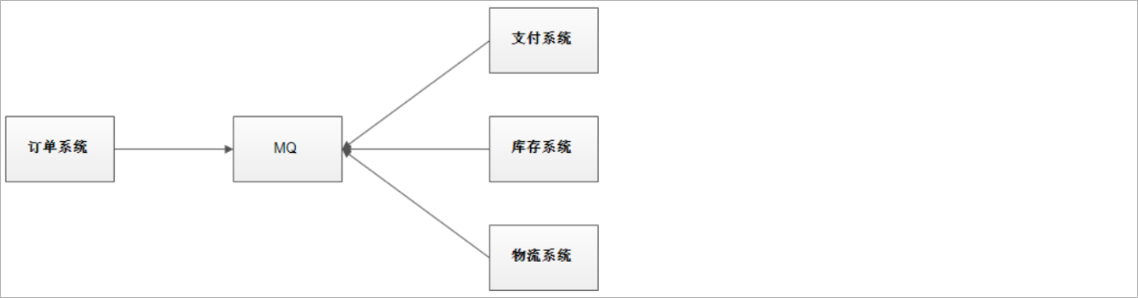
使用消息队列解耦合,系统的耦合性就会降低了,容错性就提高了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存
到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
流量消锋
流量消锋:消除系统中的高峰值流量(流量可以理解为就是请求):削峰填谷
假设用户每秒需要发送5k个请求,而我们的A系统每秒只能处理2K个请求,这样就会导致大量的下单请求失败。而且由于实际请求的数量远远超过系统的处理能力,
此时也有可能导致系统宕机。
用户每秒发送5k个请求,我们可以先将下单请求数据存储到MQ中,此时在MQ中就缓存了很多的下单请求数据,而A系统根据自己的处理能力从MQ中获取数据进行
下单操作,有了MQ的缓存层以后,就可以保证每一个用户的下单请求可以得到正常的处理,并且这样可以大大提到系统的稳定性和用户体验。
数据分发
假设A系统进行了某一个业务操作以后,需要将这个业务操作结果通知给其他的系统,原始的架构如下所示:
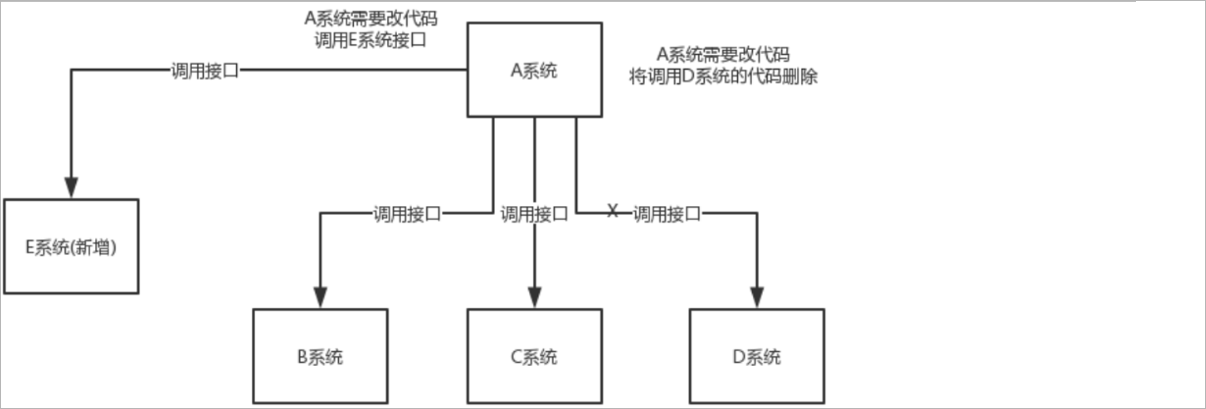
此时B系统、C系统、D系统就需要提供对应的接口,然后让A系统进行调用。如果此时不需要通知D系统了,那么就需要更改A系统的代码,将调用D系统的代码删除
掉。并且如此时项目中添加了一个新的系统E,A系统也需要将处理结构通知给E系统,那么同时也需要更改A系统的代码。这样就不利于后期的维护。
使用MQ改进以后的架构如下所示:
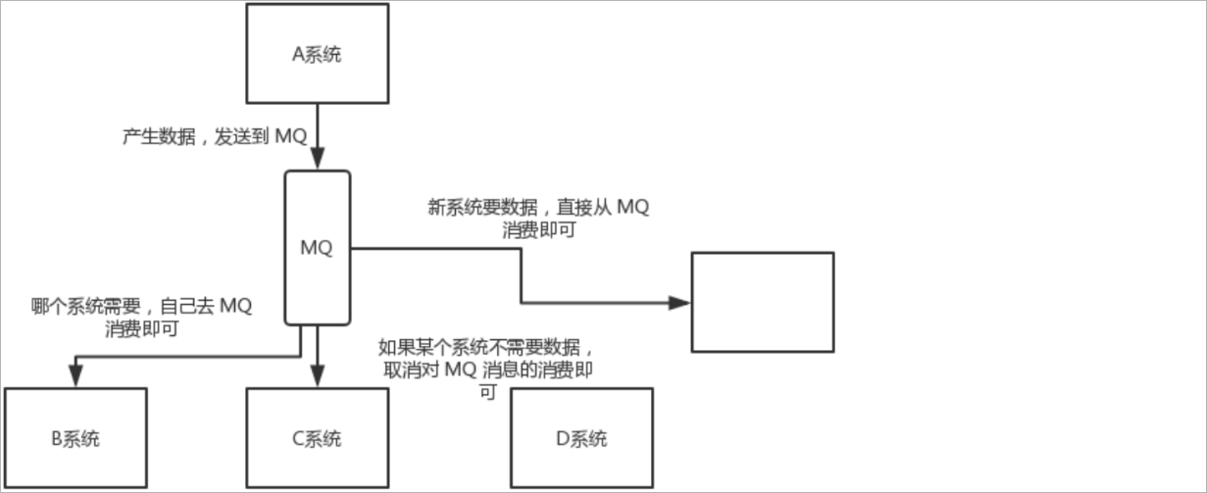
A系统需要将业务操作结果通知给其他的系统时,A系统只需要将结构发送到MQ中。其他的系统只需要从MQ中获取结果即可,如果不需要结果了,此时只需要取消
从MQ中获取结果的操作即可。并且如果新增了一个系统需要获取结果,只需要从MQ中获取结果数据就可以了,A系统的代码不需要进行改动。这样就大大的提高了
系统的维护性。
MQ的优缺点
优点:
1、应用解耦提高了系统的容错性
2、异步通讯提高了系统的响应速度
3、流量消锋提高了系统的并发能力
缺点:
1、系统可用性降低:系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
2、系统复杂度提高:MQ的加入大大增加了系统的复杂度。
MQ的选择依据是什么?
调用方是否需要获取到被调用方的执行结果,如果需要获取到结果,那么就需要使用同步通讯,如果不需要就可以使用异步通讯。
Rabbitmq简介
RabbitMQ是由erlang【二郎神】语言开发,基于AMQP(Advanced Message Queue Protocol 高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方
法,消息队列在分布式系统开发中应用非常广泛。
RabbitMQ官方地址:http://www.rabbitmq.com/
RabbitMQ常见的消息模型:https://www.rabbitmq.com/getstarted.html
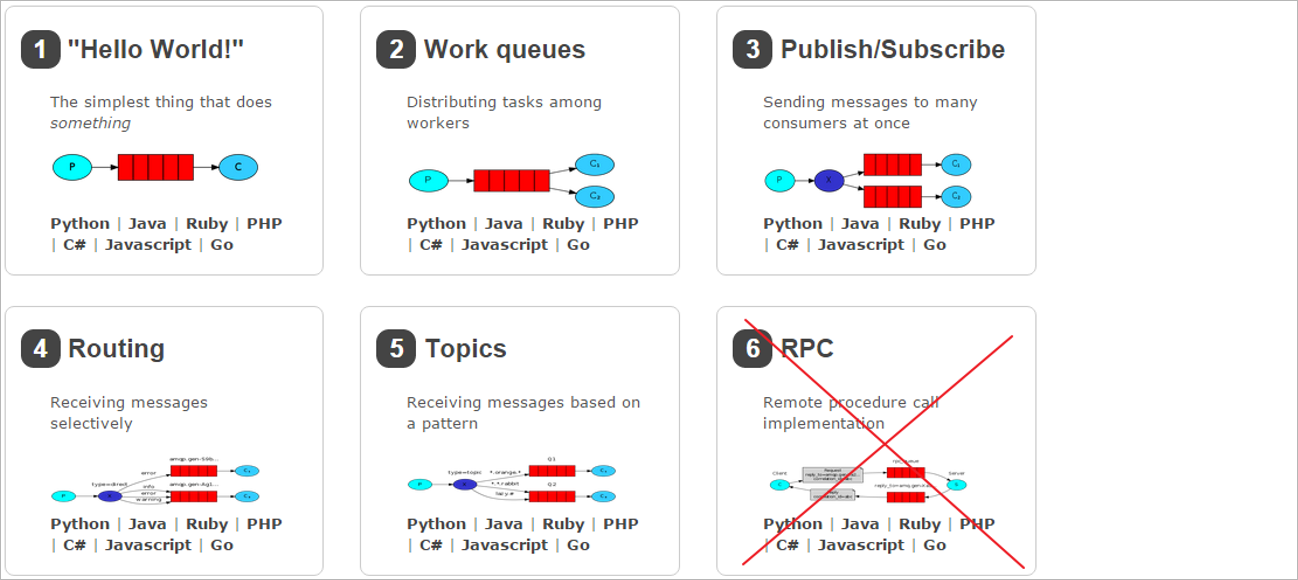
RabbitMQ提供了7种模式:简单模式,work模式 ,Publish/Subscribe发布与订阅模式,Routing路由模式,Topics主题模式,RPC远程调用模式(远程调用),生产者
确认。
常见的消息队列产品
1、ActiveMQ
2、Rabbitmq
3、RocketMQ
4、Kafka
常见特性比对:
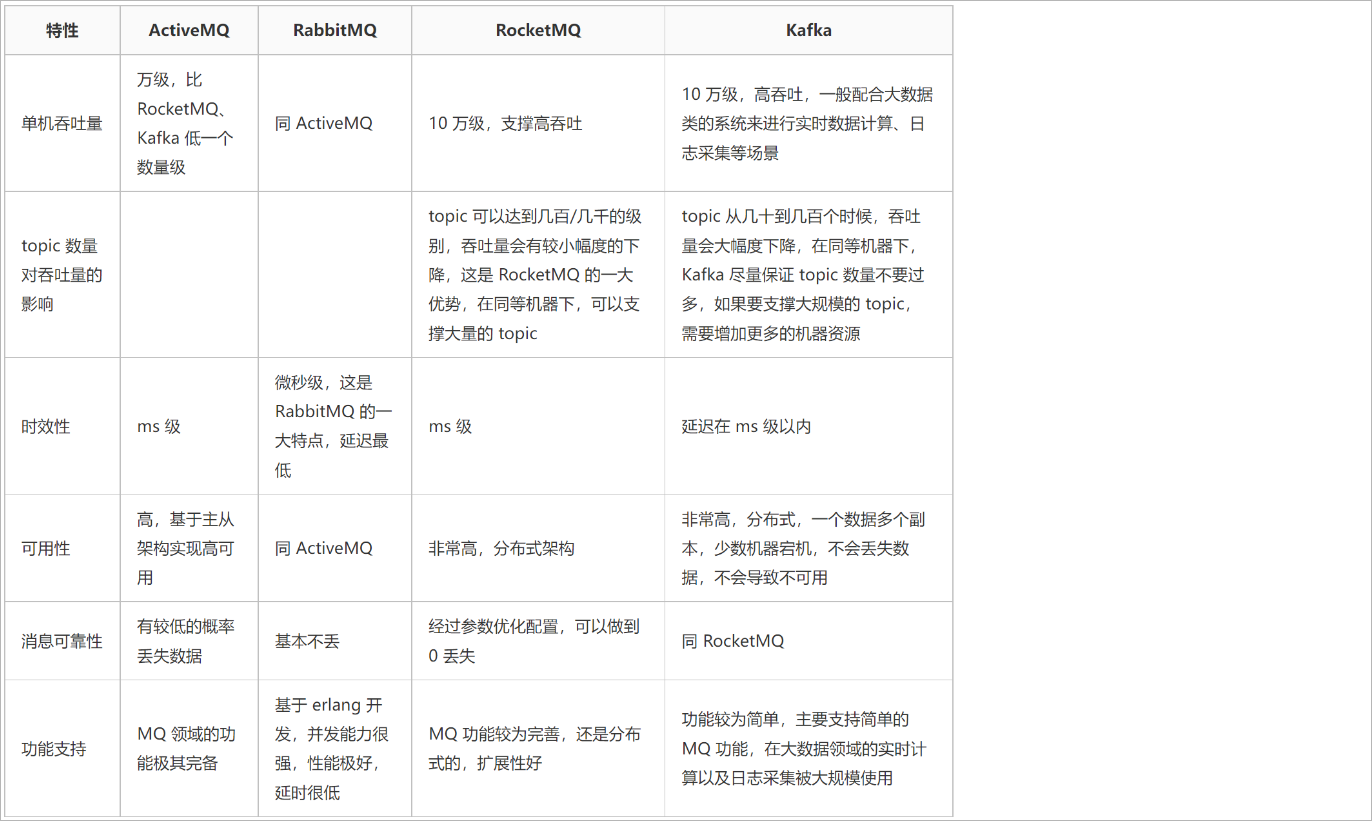
Rabbitmq环境搭建
部署Rabbitmq
架构介绍
Rabbitmq的架构图如下所示:
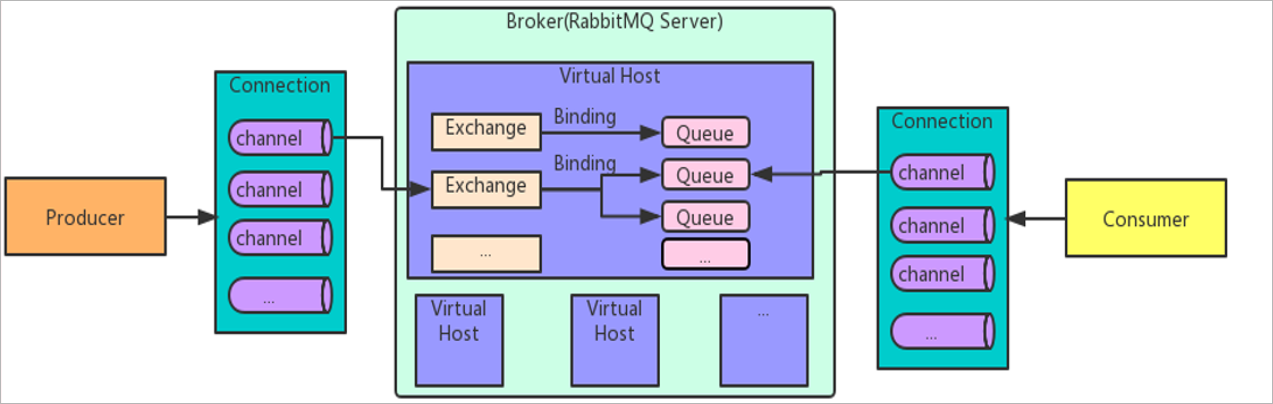
Broker:接收和分发消息的应用,RabbitMQ Server就是 Message Broker
Virtual host:出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当多个不同的用户使用同一个
RabbitMQ server 提供的服务时,可以划分出多个vhost,每个用户在自己的 vhost 创建 exchange/queue 等
Connection:publisher/consumer 和 broker 之间的 TCP 连接
Channel:如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection的开销将是巨大的,效率也较低。Channel 是在 connection
内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的 channel 进行通讯,AMQP method 包含了channel id 帮助客户端和message broker
识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection 极大减少了操作系统建立 TCP connection 的开销
Exchange:message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有:direct (point-to-point),
topic (publish-subscribe) and fanout (multicast)
Queue:存储消息的容器,消息最终被送到这里,等待 consumer 取走
Binding:exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
管理界面使用
各个选项卡的说明:
1、overview:概览
2、connections:无论生产者还是消费者,都需要与RabbitMQ建立连接后才可以完成消息的生产和消费,在这里可以查看连接情况
3、channels:通道,建立连接后,会形成通道,消息的投递获取依赖通道。
4、Exchanges:交换机,用来实现消息的路由
5、Queues:队列,即消息队列,消息存放在队列中,等待消费,消费后被移除队列
Rabbitmq常见端口号:
5672:RabbitMQ的编程语言客户端连接端口
15672:RabbitMQ管理界面端口
用户管理
常见的角色说明:
1、 超级管理员(administrator):可登录管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。
2、 监控者(monitoring):可登录管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
3、 策略制定者(policymaker):可登录管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息。
4、 普通管理者(management):仅可登录管理控制台,无法看到节点信息,也无法对策略进行管理。
5、 其他:无法登录管理控制台,通常就是普通的生产者和消费者。
虚拟主机管理
- 在哪个用户创建的虚拟主机,这个用户就拥有权限,超级管理员也可以设置权限
Rabbitmq入门
父工程
具体步骤如下所示:
1、创建一个父工程:rabbitmq-parent
2、在pom.xml文件中加入如下依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.2.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
|
生产者
具体步骤如下所示:
1、在rabbitmq-parent工程下创建一个子工程rabbitmq-producer
2、创建对应的启动类
1
2
3
4
5
6
7
8
9
|
@SpringBootApplication
public class ProducerApplication {
public static void main(String[] args) {
SpringApplication.run(ProducerApplication.class , args) ;
}
}
|
3、在application.yml文件中加入如下配置信息
1
2
3
4
5
6
7
| spring:
rabbitmq:
host: 192.168.136.145
port: 5672
username: admin
password: admin
virtual-host: /
|
4、编写测试类使用RabbitTemplate发送消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@SpringBootTest(classes = ProducerApplication.class)
public class Producer01 {
@Autowired
private RabbitTemplate rabbitTemplate ;
@Test
public void test01() {
rabbitTemplate.convertAndSend("simple_queue" , "hello rabbitmq...");
}
}
|
启动程序进行测试,需要先将队列创建出来(创建队列的三种方式:1、使用后台管理系统 2、使用Java Api 3、使用@RabbitListener注解)。
消费者工程
具体步骤如下所示:
1、在rabbitmq-parent工程下创建一个子工程rabbitmq-consumer
2、创建对应的启动类
1
2
3
4
5
6
7
8
9
10
|
@SpringBootApplication
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class , args) ;
}
}
|
3、在application.yml文件中加入如下配置信息
1
2
3
4
5
6
7
| spring:
rabbitmq:
host: 192.168.136.145
port: 5672
username: admin
password: admin
virtual-host: /
|
4、编写消费者监听方法,监听指定的队列获取队列中的消息
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Component
public class Consumer01Listener {
@RabbitListener(queues = "simple_queue")
public void consumer01(Message message) {
byte[] body = message.getBody();
String msg = new String(body);
System.out.println("msg ----> " + msg);
}
}
|
Rabbitmq消息模型
简单队列模式
一个生产者直接将消息发送到队列,一个消费者消费

工作队列
一个生产者将消息发送到队列,多个消费者共同消费一个队列中的消息
**应用场景:**对于任务过重或任务较多情况使用

发布订阅模型
- 在简单队列模型的基础上,又多了一个角色:交换机exchange
- 生产者通过将消息发送给交换机,由交换机将消息转发给队列
交换机类型
- Fanot:广播,没有binding-key,将消息转发给所有绑定的队列
- Direct:路由,把消息交给符合指定routing-key的队列
- topic:主题,把消息交给符合routing pattern (路由规则)的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Fanout
简介:fanout类型的交换机会将将消息交给所有与之绑定队列

通过java api创建exchange、queue和绑定信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
@Configuration
public class RabbitmqFanoutExchangeConfiguration {
@Bean
public Exchange fanoutExchange() {
Exchange fanoutExchange = ExchangeBuilder.fanoutExchange("fanout_exchange").durable(true).build();
return fanoutExchange ;
}
@Bean
public Queue fanoutQueue01() {
Queue queue = QueueBuilder.durable("fanout_queue_01").build();
return queue ;
}
@Bean
public Queue fanoutQueue02() {
Queue queue = QueueBuilder.durable("fanout_queue_02").build();
return queue ;
}
@Bean
public Binding fanoutQueue01Binding() {
Binding binding = BindingBuilder.bind(fanoutQueue01()).to(fanoutExchange()).with("").noargs();
return binding ;
}
@Bean
public Binding fanoutQueue02Binding() {
Binding binding = BindingBuilder.bind(fanoutQueue02()).to(fanoutExchange()).with("").noargs();
return binding ;
}
}
|
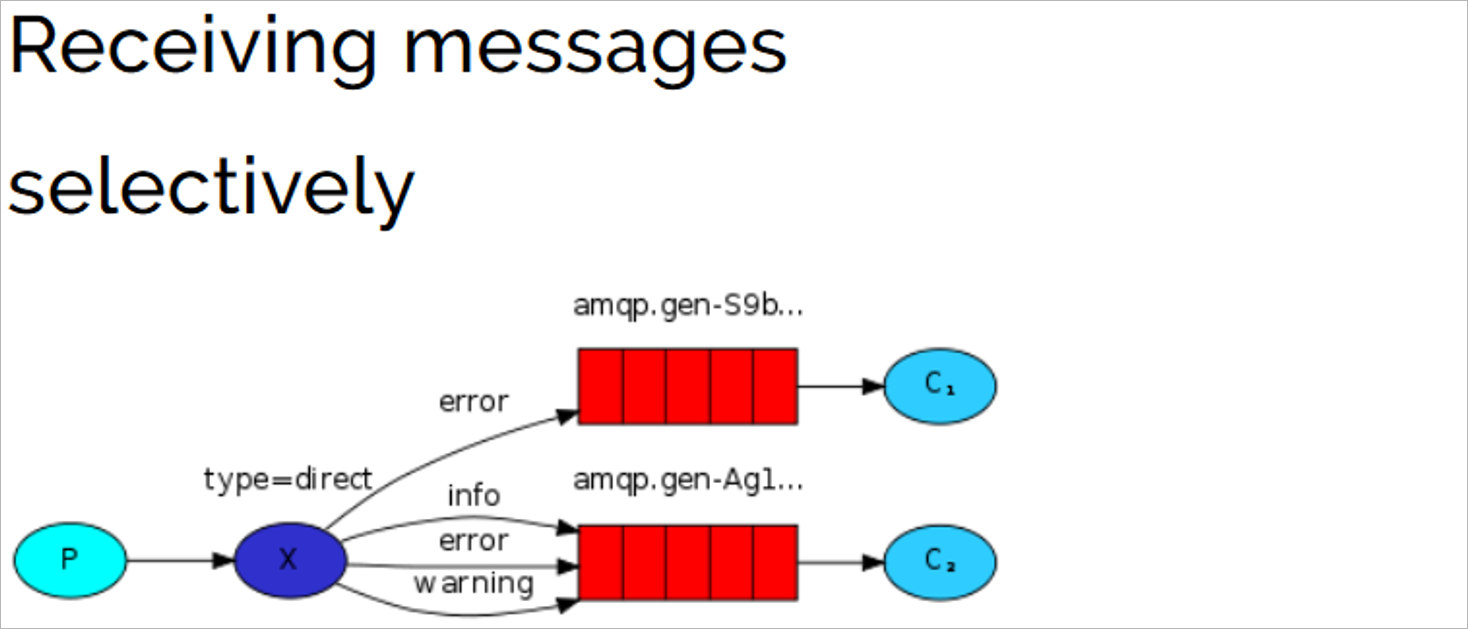
Direct
路由模式特点:
1、队列与交换机的绑定的时候需要指定一个或者多个bindingKey(routingKey)
2、生产者发送消息的时候需要指定一个消息的routingKey
3、交换机获取到消息以后需要使用消息的routingKey和bindingKey比对,如果相等就会把消息转发给对应的队列
Topic
主题模式特点:
1、队列与交换机的绑定的时候需要指定一个或者多个bindingKey(routingKey) , 在bindingKey可以使用通配符
2、生产者发送消息的时候需要指定一个消息的routingKey
3、交换机获取到消息以后需要使用消息的routingKey和bindingKey规则进行比对,如果routingKey满足bindingKey的规则就会把消息转发给对应的队列
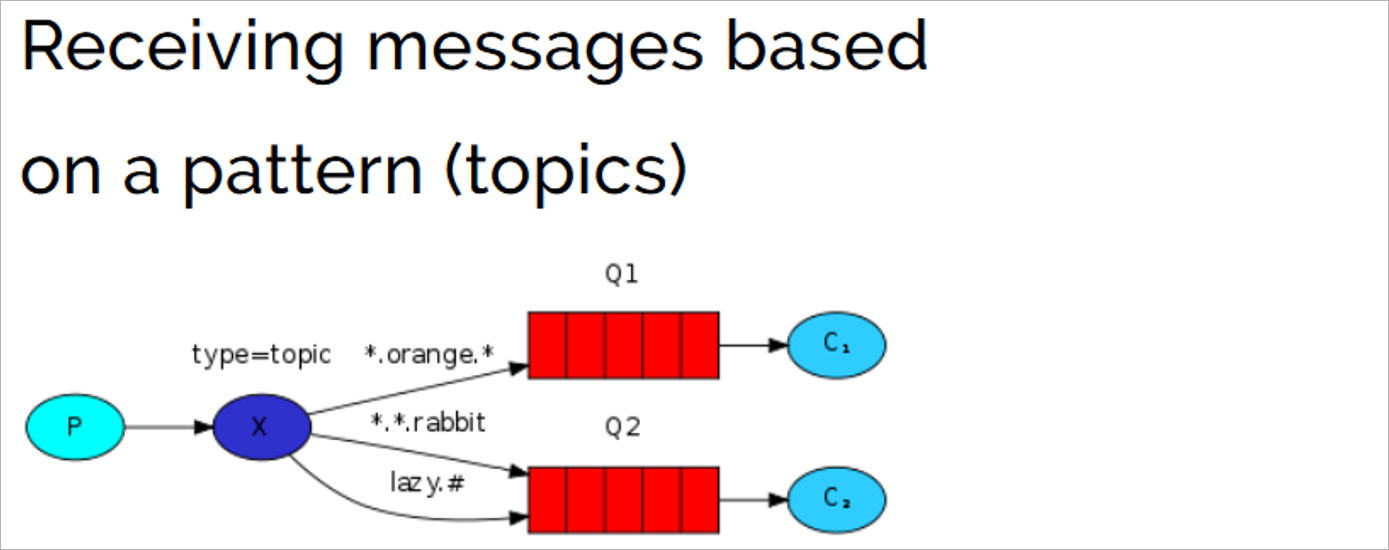
通配符介绍:
#:匹配零个或多个词
*:匹配不多不少恰好1个词
@RabbitListener注解
RabbitListener注解用来声明消费者监听器,可以监听指定的队列,同时也可以声明队列、交换机、队列和交换机绑定信息。
代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@Component
public class Consumer02Listener {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "direct_queue_02" , durable = "true") ,
exchange = @Exchange(value = "direct_exchange" , durable = "true" , type = ExchangeTypes.DIRECT) ,
key = { "error" , "info"}
))
public void consumer01(Message message) {
byte[] body = message.getBody();
String msg = new String(body);
System.out.println("consumer02Listener....msg ----> " + msg);
}
}
|
消息的可靠性保证
概述:指的就是在整个消息的传输过程中如何保证消息不丢失!

1、生产者发送消息到MQ:交换机的名字写错了、routingKey写错了
2、MQ服务端存储消息: MQ服务器宕机了(默认情况下消息是存储于内存中)
3、消费者从MQ中消费消息:消费者获取到消息以后还没有及时处理,消费者服务宕机了
消息可靠性投递
生产者发送消息的时候有两个阶段:
1、生成者发生消息到exchange
2、交换机获取到消息以后把消息转发到队列中
针对上的两个阶段Rabbitmq提供了两种机制保障消息的可靠性投递:
confirm 确认模式:可以通过该机制确认消息是否可以正常发送到exchange:

return 退回模式:可以通过该机制确认消息是否可以正常发送到队列中

confirm
如下所示:
1、在配置文件中开启生产者确认机制
1
2
3
| spring:
rabbitmq:
publisher-confirm-type: correlated
|
2、自定义RabbitTemplate,并为其绑定确认机制的回调函数,让生产者可以感知到消息是否正常投递给了交换机
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@Configuration
public class RabbitTemplateConfiguration {
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory) ;
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if(ack) {
System.out.println("消息正常发给交换机了...");
}else {
String msgId = correlationData.getId();
System.out.println("消息发送给交互机失败了...msgId ---> " + msgId);
}
}
});
return rabbitTemplate ;
}
}
|
3、发送消息
1
2
3
4
5
6
7
8
9
10
11
| @Test
public void test01() {
String msgId = UUID.randomUUID().toString().replace("-", "");
CorrelationData correlationData = new CorrelationData(msgId) ;
rabbitTemplate.convertAndSend("direct_exchange2" , "error" , "hello direct exchange...." , correlationData);
}
|
return机制
如下所示:
1、在配置文件中开启生产者回退机制
1
2
3
| spring:
rabbitmq:
publisher-returns: true
|
2、自定义RabbitTemplate,并为其绑定回退机制的回调函数,让生产者可以感知到消息是否正常投递给了队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
rabbitTemplate.setMandatory(true);
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returnedMessage) {
String exchange = returnedMessage.getExchange();
String routingKey = returnedMessage.getRoutingKey();
Message message = returnedMessage.getMessage();
int replyCode = returnedMessage.getReplyCode();
String replyText = returnedMessage.getReplyText();
String msg = new String(message.getBody()) ;
String correlationId = (String)message.getMessageProperties().getHeaders().get("spring_returned_message_correlation");
System.out.println("correlationId:"+correlationId);
System.out.println("消息投递给队列失败了, msg ---> " + msg);
System.out.println("replyCode ---> " + replyCode);
System.out.println("replyText ---> " + replyText);
System.out.println("exchange ---> " + exchange);
System.out.println("routingKey ---> " + routingKey);
}
});
|
3、发送消息
1
2
3
4
5
6
7
8
9
10
11
| @Test
public void test01() {
String msgId = UUID.randomUUID().toString().replace("-", "");
CorrelationData correlationData = new CorrelationData(msgId) ;
rabbitTemplate.convertAndSend("direct_exchange" , "error2" , "hello direct exchange...." , correlationData);
}
|
消息可靠性存储
针对MQ服务端存储消息导致消息丢失的情况,那么此时只需要对如下的对象进行持久化即可。
1、消息开启持久化
2、队列开启持久化
3、交换机开启持久化
注意:Spring boot整合RabbitMQ默认的情况下创建的队列以及发送的消息都是持久化的。
设置消息为非持久化消息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Test
public void test01() {
String msgId = UUID.randomUUID().toString().replace("-", "");
CorrelationData correlationData = new CorrelationData(msgId) ;
MessagePostProcessor messagePostProcessor = new MessagePostProcessor(){
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);
return message;
}
} ;
rabbitTemplate.convertAndSend("direct_exchange" ,
"error" ,
"hello direct exchange...." ,
messagePostProcessor , correlationData );
}
|
消息可靠性消费
消费者获取到消息以后需要给RabbitMQ服务端进行应答,RabbitMQ根据消费者的应答信息决定是否需要将消息从RabbitMQ的服务端删除掉。
应答模式:
1、none: 进行自动应答,消费者获取到消息以后直接给RabbitMQ返回ack,RabbitMQ直接将消息从队列中删除掉
2、manual: 手动应答,消费者可以根据消息消费的实际情况给RabbitMQ进行应答
3、auto(默认值):由Spring容器来根据业务的执行特点进行对应的应答,如果业务执行正常,返回ack,业务执行异常,返回unack。
none模式
在消费者的application.yml文件中,设置消息者应答模式为none模式,如下所示:
1
2
3
4
5
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: none
|
auto模式(默认模式)
在消费者的application.yml文件中,设置消息者应答模式为auto模式,如下所示:
1
2
3
4
5
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: auto
|
注意:
1、测试重试的时候不能通过异常的输出次数来判断方法调用了几次。
2、重试次数耗尽以后会调用MessageRecoverer中的recover方法对消息进行处理掉。
- RejectAndDontRequeueRecoverer:拒绝而且不把消息重新放入队列(默认)
- RepublishMessageRecoverer:重新发布消息
manual模式
auto模式当重试次数耗尽以后,消息的处理还是失败,直接将消息从RabbitMQ服务端删除掉,相当于消息丢失。那么针对这种情况最好使用manual模式。
在消费者的application.yml文件中,设置消息者应答模式为manual模式,如下所示:
1
2
3
4
5
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual
|
代码测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| @Component
public class Consumer01Listener {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "direct_queue_01" , durable = "true") ,
exchange = @Exchange(value = "direct_exchange" , durable = "true" , type = ExchangeTypes.DIRECT) ,
key = "error"
))
public void consumer01(Message message , Channel channel) {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
byte[] body = message.getBody();
String msg = new String(body);
try {
String correlationId = message.getMessageProperties().getCorrelationId();
System.out.println("consumer01Listener ...msg ----> " + msg);
int a = 1 / 0 ;
channel.basicAck(deliveryTag , true);
}catch (Exception e) {
e.printStackTrace();
try {
channel.basicNack(deliveryTag , true , true);
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
|
注意:业务代码产生了异常,消息不会从RabbitMQ服务端删除掉,但是出现了无限次消费的情况。
解决方案:设置最大重试次数(手动实现)、需要配合Redis。
1
2
3
4
5
| /**
* 解决死循环:指定最大的重试次数
* 消息的实际消费次数该怎么计算?借助于redis
* 一旦消息的实际消费次数 大于 指定的最大的重试次数,那么此时需要给rabbitmq返回ack, 在返回之前需要把消息写入到数据库中,后期人工处理。
*/
|
消费者限流
具体实现:在消费者的application.yml配置文件中加入如下的配置
1
2
3
4
5
6
| spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual
prefetch: 10
|
消息存活时间
TTL 全称 Time To Live(存活时间/过期时间)。
当消息在队列中时间到达存活时间后,还没有被消费,会被自动清除。
RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间。
给消息设置存活时间:
1
2
3
4
5
6
7
8
9
| MessagePostProcessor messagePostProcessor=new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setExpiration("10000");
message.getMessageProperties().setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT);
return message;
}
};
rabbitTemplate.convertAndSend("fanout_exchange","","1213",messagePostProcessor);
|
注意:MQ默认只会把队列首部的消息进行是否过期验证,如果一条消息已经过期,但是不在队列首部,队列也不会将其移除出去。
给队列设置消息存储时间:
1
2
3
4
5
6
| @Bean
Queue ttlQueue01(){
return QueueBuilder.durable("ttl_queue01").
ttl(10000).
build();
}
|
1
2
3
4
5
6
7
| @RabbitListener(queuesToDeclare= @Queue(value = "ttl_queue02",
arguments = @Argument(name = "x-message-ttl", value = "10000", type = "java.lang.Long")
))
public void ttlQueue02(Message message){
String msg=new String(message.getBody());
System.out.println("msg = " + msg);
}
|
死信队列
死信:死掉的消息
消息成为死信的三种情况
1、队列消息数量到达限制;比如队列最大只能存储10条消息,而发了11条消息,根据先进先出,最先发的消息成为死信。
2、消费者拒接消费消息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false;
3、原队列存在消息存活时间设置,消息到达存活时间未被消费;
注意:默认情况下Rabbitmq会直接将死信丢弃掉,但是如果在系统中提供了死信队列,那么此时就会把消息投递给死信队列。
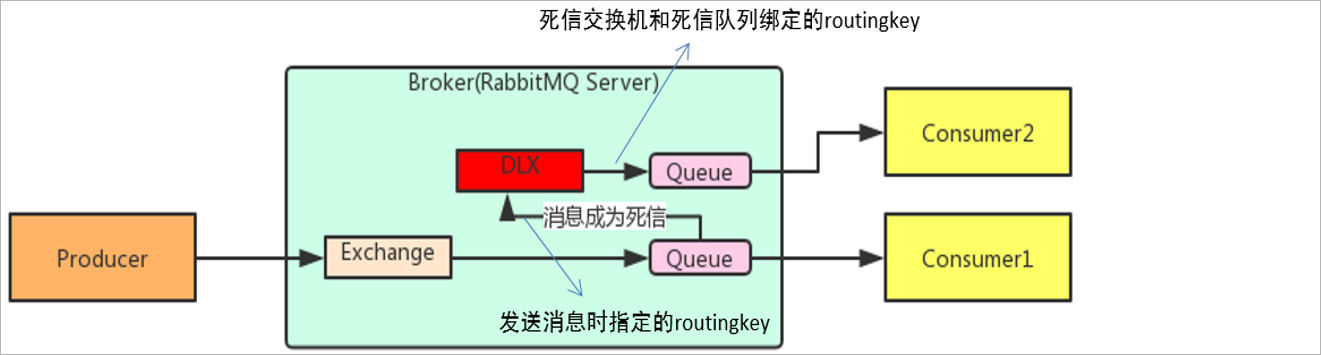
在存储死信到死信队列的时候,需要使用到死信交换机:
DeadLetter Exchange(死信交换机),英文缩写:DLX 。当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX。后期这个交换机
就可以将消息投递到与之绑定的死信队列中。
如下图所示:
代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
@Bean
public Exchange dlxExchange() {
Exchange dlx = ExchangeBuilder.directExchange("dlx_exchange").durable(true).build();
return dlx ;
}
@Bean
public Queue dlxQueue() {
Queue queue = QueueBuilder.durable("dlx_queue").build();
return queue ;
}
@Bean
public Binding dlxQueueBinding() {
Binding binding = BindingBuilder.bind(dlxQueue()).to(dlxExchange())
.with("dlx").noargs();
return binding ;
}
@Bean
public Queue directQueue01() {
Queue queue = QueueBuilder.durable("direct_queue_01")
.maxLength(10)
.deadLetterExchange("dlx_exchange")
.deadLetterRoutingKey("dlx")
.build();
return queue ;
}
|
延迟队列
延迟队列存储的对象肯定是对应的延时消息,所谓延时消息是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
场景:在订单系统中,一个用户下单之后通常有30分钟的时间进行支付,如果30分钟之内没有支付成功,那么这个订单将进行取消处理。这时就可以使用延时队列将
订单信息发送到延时队列。

在RabbitMQ中并未提供延迟队列功能。但是可以使用:ttl +死信队列 组合实现延迟队列的效果。
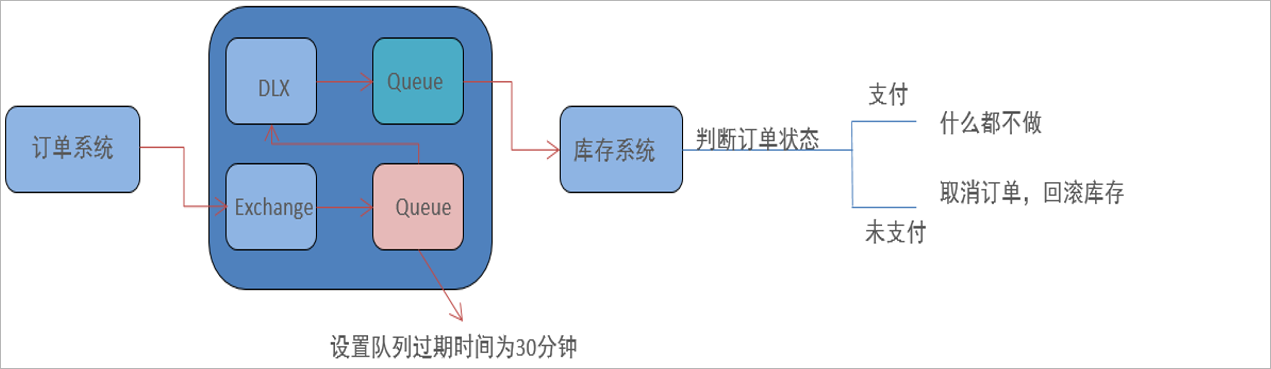
当然延迟队列还有其他应用场景:
1.公众号文章的延迟发布
2.邮件的延迟发送
3.订单超时30分钟未支付自动取消订单
消息的重复消费问题
消息百分百成功投递架构
针对一些特殊的业务,要严格保证消息能够进行正常传输。那么此时在进行消息投递的时候,就可以使用如下的架构保证消息百分百成功投递:
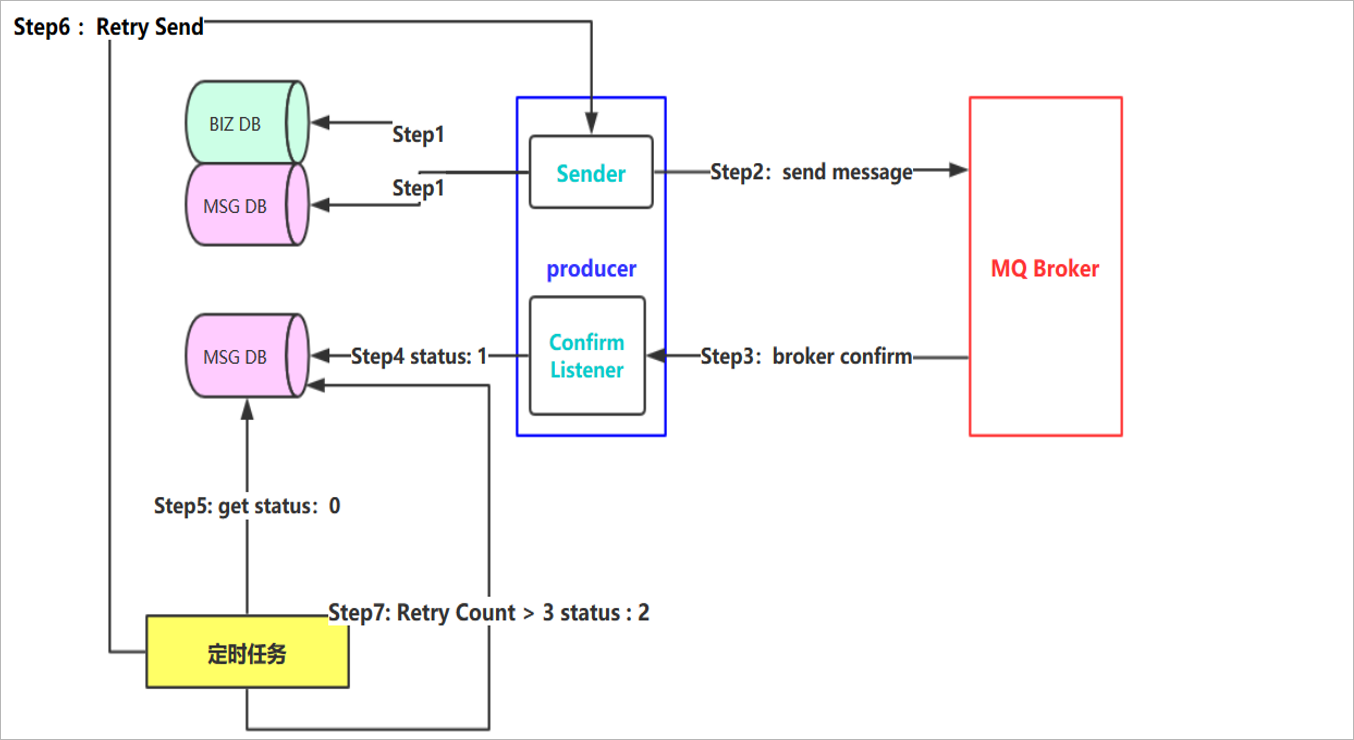
Step 1: 首先把消息信息(业务数据)存储到数据库中,紧接着,我们再把这个消息记录也存储到一张消息记录表里(或者另外一个同源数据库的消息记录表),并且
在消息数据库表中需要指定一个状态字段status来记录消息的投递状态。
Step 2:发送消息到MQ Broker节点(采用confirm方式发送,会有异步的返回结果)
Step 3、4:生产者端接受MQ Broker节点返回的Confirm确认消息结果,然后进行更新消息记录表里的消息状态。比如默认Status = 0 当收到消息确认成功后,更
新为1即可!
Step 5:但是在消息确认这个过程中可能由于网络闪断、MQ Broker端异常等原因导致 回送消息失败或者异常。这个时候就需要发送方(生产者)对消息进行可靠
性投递了,保障消息不丢失,100%的投递成功!(有一种极限情况是闪断,Broker返回的成功确认消息,但是生产端由于网络闪断没收到,这个时候重新投递可能
会造成消息重复,需要消费端去做幂等处理)所以我们需要有一个定时任务,(比如每5分钟拉取一下处于中间状态的消息,当然这个消息可以设置一个超时时间,比
如超过1分钟 Status = 0 ,也就说明了1分钟这个时间窗口内,我们的消息没有被确认,那么会被定时任务拉取出来)
Step 6:接下来我们把中间状态的消息进行重新投递 retry send,继续发送消息到MQ ,当然也可能有多种原因导致发送失败
Step 7:我们可以采用设置最大努力尝试次数,比如投递了3次,还是失败,那么我们可以将最终状态设置为Status = 2 ,最后 交由人工解决处理此类问题(或者把
消息转储到失败表中)。
情况一:投递过程中产生了网络抖动不会导致消息丢失(因为消息已经入库)
情况二:confirm回执的时候产生了网络抖动不会导致消息丢失(因为消息已经入库)
具体思路:如果想实现消息的百分百投递:
- 就需解决在投递过程中如果消息丢失,这时就需要在发送消息的一端将消息持久化保存,记录状态,只有消息成功执行之后执行回调时改变状态,代表消息是否已经被消费,如果没有,则可以采用定时任务去执行那些状态为未被消化的消息
- 如果在执行回调时丢失,说明消息已经被消费,但是状态未成功改变,此时就可能发生消息 的重复消费
数据库表设计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| DROP TABLE IF EXISTS `broker_message_log`;
CREATE TABLE `broker_message_log` (
`message_id` varchar(255) NOT NULL COMMENT '消息唯一ID',
`message` varchar(4000) NOT NULL COMMENT '消息内容',
`try_count` int(4) DEFAULT '0' COMMENT '重试次数',
`status` varchar(10) DEFAULT '' COMMENT '消息投递状态 0投递中,1投递成功,2投递失败',
`next_retry` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP COMMENT '下一次重试时间',
`create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`message_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`message_id` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2018091102 DEFAULT CHARSET=utf8;
|
消息的重复消费问题
采用上述架构实现消息的投递,那么此时就会出现消息的重复消费问题。
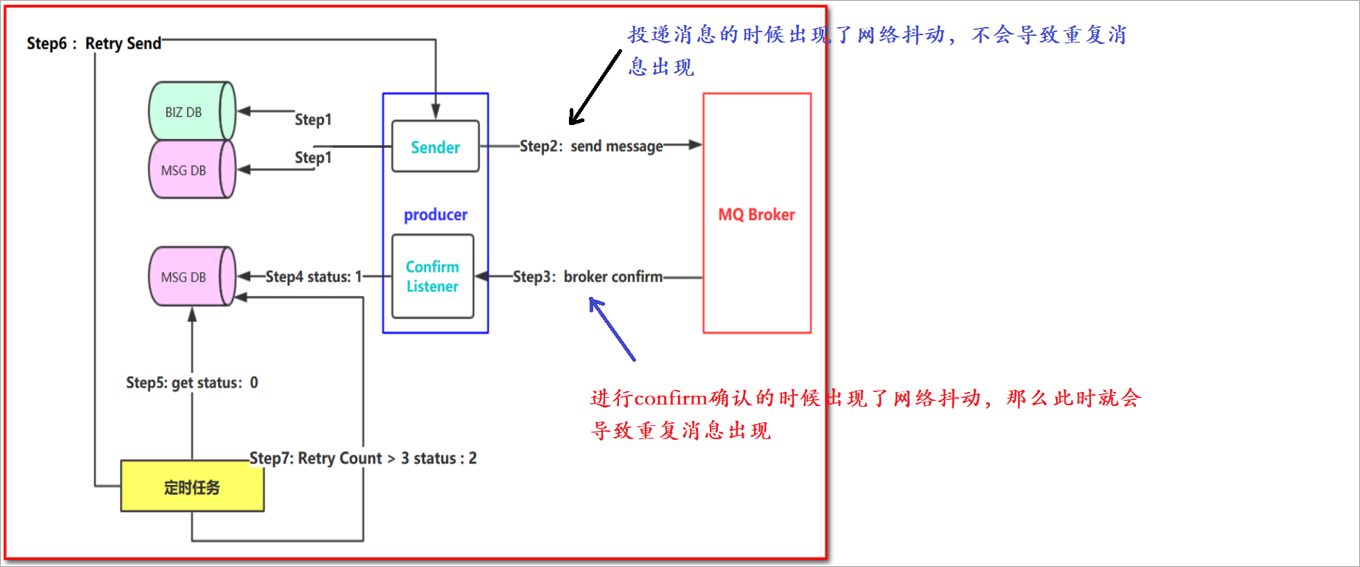
MQ中出现了重复消息,那么此时就会导致重复消费问题。在有一些特殊的业务场景下,是不允许出现重复消息的,比如扣减库存。
幂等性处理
**幂等性指一次和多次请求某一个资源对于资源本身应该具有同样的结果。**也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
在MQ中指,消费多条相同的消息,得到与消费该消息一次相同的结果。
消息幂等性保障 :数据库唯一字段
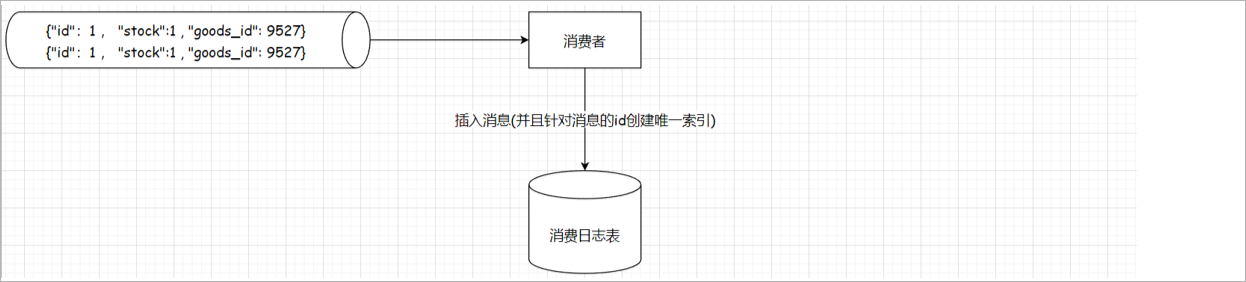
具体思路: 为了实现消息的百分百成功投递,就可能会发生消息的重复消费,
解决思路: 幂等性处理,具体实现就是在消息的消费方,将所有消费的消息进行持久化记录,每一个消息都有它的唯一的id,当有重复的消息传递过来时,先去查找,如果存在相同id,就不进行消费。
消息的重发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
| package com.spzx.common.rabbit.config;
import com.spzx.common.rabbit.domain.CorrelationRetryData;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.ApplicationListener;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.concurrent.TimeUnit;
import static com.spzx.common.rabbit.Constants.MqConstants.RABBIT_MQ_KEY;
@Slf4j
@Configuration
public class RabbitConfig implements ApplicationListener<ApplicationReadyEvent> {
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
RedisTemplate redisTemplate;
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
setConfirm();
setReturn();
}
void setConfirm(){
this.rabbitTemplate.setConfirmCallback(((correlationData, ack, cause) -> {
if (ack) {
log.info("消息发送到交换机");
}else {
log.error("消息没有发送到交换机:{}",cause);
retrySend(correlationData);
}
}));
}
private void setReturn(){
this.rabbitTemplate.setReturnsCallback(returned -> {
log.error("消息没有发送到队列:{}",returned);
String retryDataId = returned.getMessage().getMessageProperties().getHeader("spring_returned_message_correlation");
CorrelationRetryData retryData = (CorrelationRetryData) redisTemplate.opsForValue().get(RABBIT_MQ_KEY+retryDataId);
if (retryData.isDelay()) {
log.info("延迟消息");
return;
}
retrySend(retryData);
});
}
private void retrySend(CorrelationData correlationData){
CorrelationRetryData retryData= (CorrelationRetryData) correlationData;
int retryCount = retryData.getRetryCount();
String exchange = retryData.getExchange();
Object message = retryData.getMessage();
String routingKey = retryData.getRoutingKey();
int delayTime = retryData.getDelayTime();
String retryDataId = retryData.getId();
if (retryCount >=3) {
log.error("管理员介入:{}",retryData);
return;
}
if(retryData.isDelay()){
rabbitTemplate.convertAndSend(exchange,routingKey,message,message1 -> {
message1.getMessageProperties().setDelay((int) (delayTime*1000));
return message1;
},retryData);
redisTemplate.opsForValue().set(RABBIT_MQ_KEY+retryDataId,retryData,10, TimeUnit.MINUTES);
return;
}
retryData.setRetryCount(++retryCount);
rabbitTemplate.convertAndSend(exchange,routingKey,message,retryData);
redisTemplate.opsForValue().set(RABBIT_MQ_KEY+retryDataId,retryData,10, TimeUnit.MINUTES);
log.info("重发,第{}次",retryCount);
}
}
|

