
Sentinel
Sentinel
服务雪崩
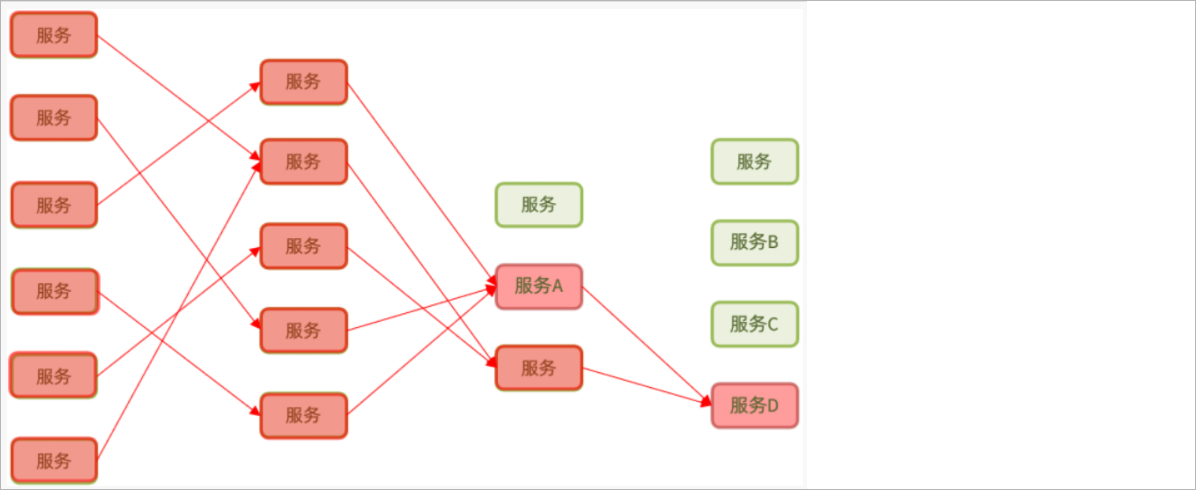
概述:在微服务系统架构中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。一个服务的不可用导致整个系统的不可用的现象就被称之为雪崩效应。
如下图所示:
解决方案
超时处理
超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
隔离处理
隔离处理:将错误隔离在可控的范围之内,不要让其影响到其他的程序的运行。
熔断处理
熔断处理:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
流量控制
流量控制:限制业务访问的QPS(每秒的请求数),避免服务因流量的突增而故障。
整合sentinel
我们在spzx-cloud-user中整合sentinel,并连接sentinel的控制台,步骤如下:
1、引入sentinel依赖
1 | <!--sentinel--> |
2、配置控制台
修改application.yaml文件,添加下面内容
1 | spring: |
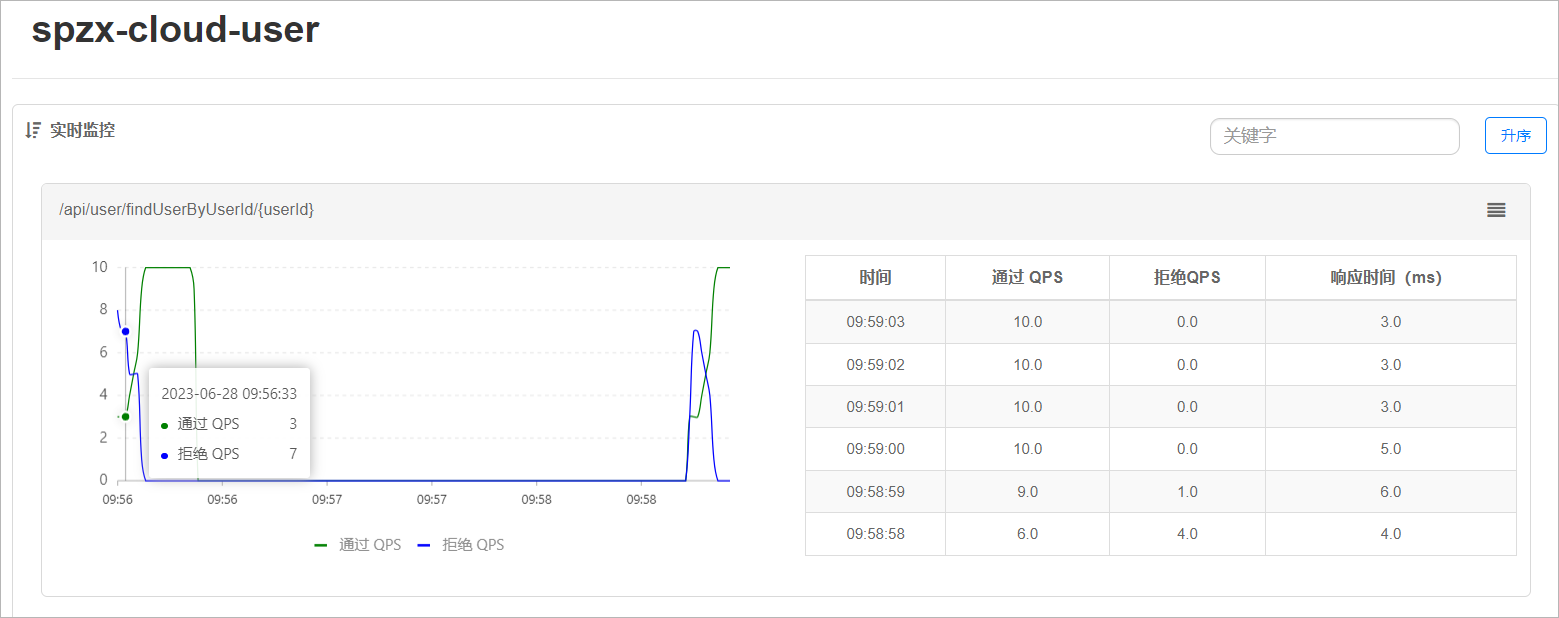
3、访问spzx-cloud-user的任意接口
打开浏览器,访问http://localhost:10100/api/user/findUserByUserId/1,这样才能触发sentinel的监控。然后再访问sentinel的控制台,查看效果:
流控模式
控模式简介
在添加限流规则时,点击高级选项,可以选择三种流控模式:
1、直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
2、关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
3、链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
关联模式
关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
语法说明:对/api/user/updateUserById资源的请求进行统计,当访问流量超过阈值时,就对/api/user/findUserByUserId/{userId}进行限流,避免影响/api/user/updateUserById资源。
使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是优先支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
关联流控模式的使用场景:
1、两个有竞争关系的资源
2、一个优先级较高,一个优先级较低
对高优先级的资源的流量进行统计,当超过阈值对低优先级的资源进行限流。
链路模式
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值,如果超过阈值对从该链路请求进行限流。
配置方式:
1、/api/user/save --> users
2、/api/user/query --> users
实际场景
当多个cantoller访问同一个资源时(自定义名称,在service上),实现对其中某些请求路径做流控,
-
在需要进行流控的资源上标记资源名称
通过**@SentinelResource**标记UserService中的queryUsers方法为一个sentinel监控的资源(默认情况下,sentinel只监控controller方法)
-
更改application.yml文件中的sentinel配置
链路模式中,是对不同来源的两个链路做监控。但是sentinel默认会给进入spring mvc的所有请求设置同一个root资源,会导致链路模式失效。因此需要关闭这种资源整合。
1
2
3
4spring:
cloud:
sentinel:
web-context-unify: false # 关闭context整合 -
对资源进行流控,添加流控规则
流控效果
流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
1、快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常,是默认的处理方式
2、warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常,但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值
3、排队等待:让所有的请求按照先后次序进入到一个队列中进行排队,当某一个请求最大的预期等待时间超过了所设定的超时时间时同样是拒绝并抛出异常
warm up
阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到最大值,可能导致服务瞬间宕机。
warm up也叫预热模式,是应对服务冷启动的一种方案。阈值会动态变化,从一个较小值逐渐增加到最大阈值。
工作特点:请求阈值初始值是 maxThreshold / coldFactor, 持续指定时长(预热时间)后,逐渐提高到maxThreshold值,而coldFactor的默认值是3。
排队等待
排队等待:让所有的请求按照先后次序进入到一个队列中进行排队,当某一个请求最大的预期等待时间超过了所设定的超时时间时同样是拒绝并抛出异常
例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
1、第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
2、第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
热点参数限流
配置介绍
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
对同一个接口,不同的参数进行限流
实现步骤:
1、标记资源
给UserController中的/api/user/findUserByUserId/{userId}资源添加注解:
1 | // 声明资源名称 |
2、设置热点参数限流规则
可以给资源设置默认的规则,也可以对特殊参数设置对应的规则
服务降级
隔离处理:将错误隔离在可控的范围之内,不要让其影响到其他的程序的运行。
案例演示
为了让测试效果更加明显一点,可以让访问/api/user/findUserByUserId/{userId}接口的线程出异常,然后用jemeter给spzx-cloud-order服务中的调用用户微服务的接口发送请求。
1 |
|
会发现报错,上述请求失败以后,直接返回返回500的错误状态码给用户,而这个错误请求并不是由于用户访问查询订单信息报错导致的,而是由于根据订单查询用户时报错的。因此直接给用户返回500的错误状态码其实不太友好,友好的做法当远程调用失败以后,返回一个默认的用户信息给前端,这种备用方案就是我们的降级方案。服务降级,如下所示:
实现步骤:
1、在spzx-cloud-order微服务中添加sentinel的依赖
1 | <!--sentinel--> |
2.并spzx-cloud-order微服务的application.yml文件中
1 | # 微服务整合sentinel |
实现步骤:
1、在spzx-cloud-order模块中定义一个类让其实现UserFeignClient接口,重写queryById方法,在该方法中编写降级逻辑
1 | // com.atguigu.spzx.cloud.feign.fallback; |
2、在UserFeignClient接口中注册配置该降级类
1 |
|
3、把该降级类纳入到spring容器中
方案一:在spzx-cloud-order的启动类上通过@Import注解进行导入
方案二:使用Spring Boot3的自动化配置原理完成,SPI机制。
即:在resources目录下创建一个META-INF/spring文件夹,在该文件夹下创建一个org.springframework.boot.autoconfigure.AutoConfiguration.imports文件,文件的中的内容如下所示:
1 | com.atguigu.spzx.feign.order.fallback.UserFeignClientFallback |
方案三:直接在UserFeignClientFallback类上加@Component注解。
4、在spzx-cloud-order微服务的application.yml文件中
1 | # feign整合sentinel:第四步 |
4、重启服务,重新配置隔离规则,并进行测试
熔断处理
原理
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、异常数、慢请求比例,如果超出阈值则会熔断该服务。即拦截访
问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
断路器(熔断器)控制熔断和放行是通过状态机来完成的:
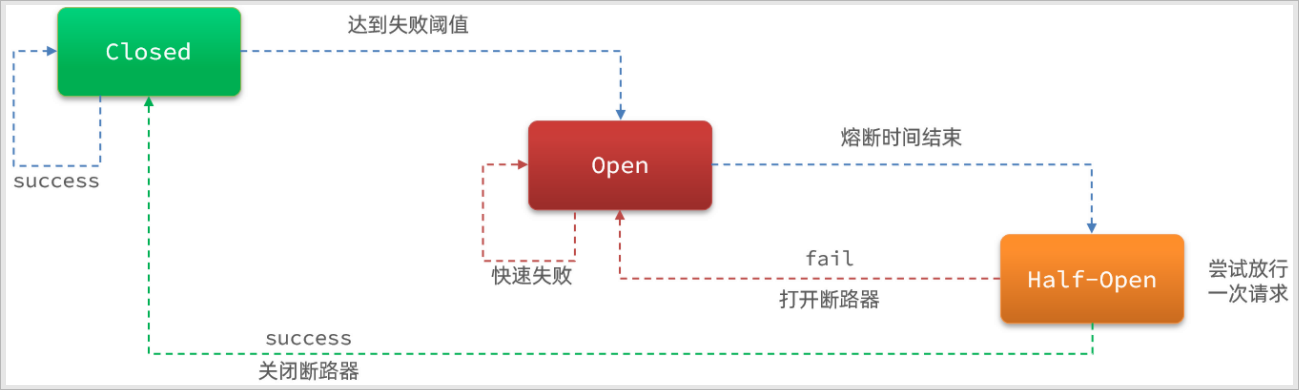
状态机包括三个状态:
1、closed:关闭状态,断路器放行所有请求,并开始统计异常比例、异常数、慢请求比例。超过阈值则切换到open状态
2、open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
3、half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
① 请求成功:则切换到closed状态
② 请求失败:则切换到open状态
断路器熔断判断策略有三种:慢调用、异常比例、异常数
慢调用比例
慢调用**:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。sentinel会统计指定时间内,请求数量超过设定的最小数量的请求并且慢调
用比例的比例。
如果慢调用比例大于设定的阈值,则触发熔断。
异常比例和异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
自定义sentinel异常结果
默认情况下,发生限流、降级、授权拦截时,都会抛出异常到调用方。如果要自定义异常时的返回结果,需要实现BlockExceptionHandler 接口:
1 | public interface BlockExceptionHandler { |
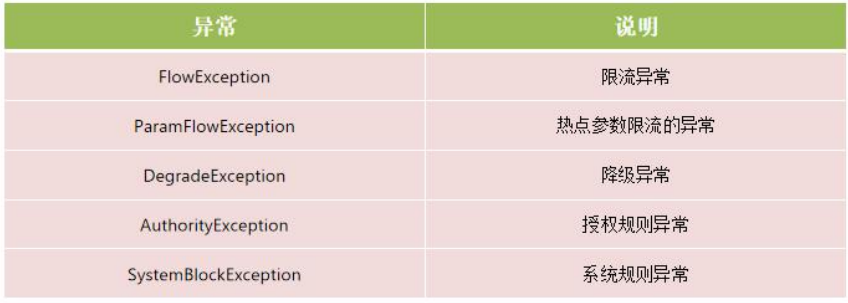
而 BlockException 包含很多个子类,分别对应不同的场景:
我们在 用户微服务 中定义类,实现 BlockExceptionHandler 接口:
1 | package com.atguigu.cloud.user.controller; |
注:在上面的自定义类中,如果不需要返回自定义的响应结果,而是跳转到对应页面,可以将返回结果处理换成方法中最后的两种处理方法即可。
规则持久化
规则持久化概述
默认情况下sentinel没有对规则进行持久化,让对服务进行重启以后,Sentinel规则将消失,生产环境需要将配置规则进行持久化
持久化思想:将限流配置规则持久化进Nacos保存,只要刷新spzx-cloud-order某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对spzx-cloud-order上Sentinel上的流控规则持续有效
Nacos添加规则配置
在nacos配置中心中添加规则配置
规则配置内容如下所示:
1 | [ |
规则说明:
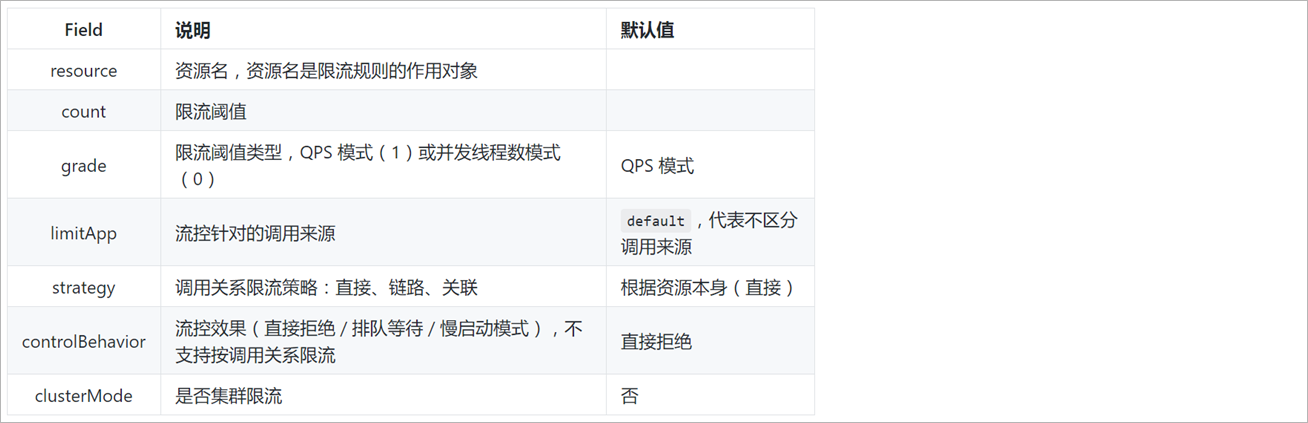
读取nacos规则配置
微服务可以从nacos配置中心读取规则配置信息然后进行使用。
具体步骤如下所示:
1、在spzx-cloud-order微服务中的pom.xml文件中添加如下依赖
1 | <dependency> |
2、在spzx-cloud-order微服务的application.yml文件添加如下配置
1 | # 配置数据库的连接信息 |
3、重启spzx-cloud-order微服务,访问任意一个接口,此时就可以在sentinel的控制台看到对应的流控规则了