高性能架构模式
读写分离架构
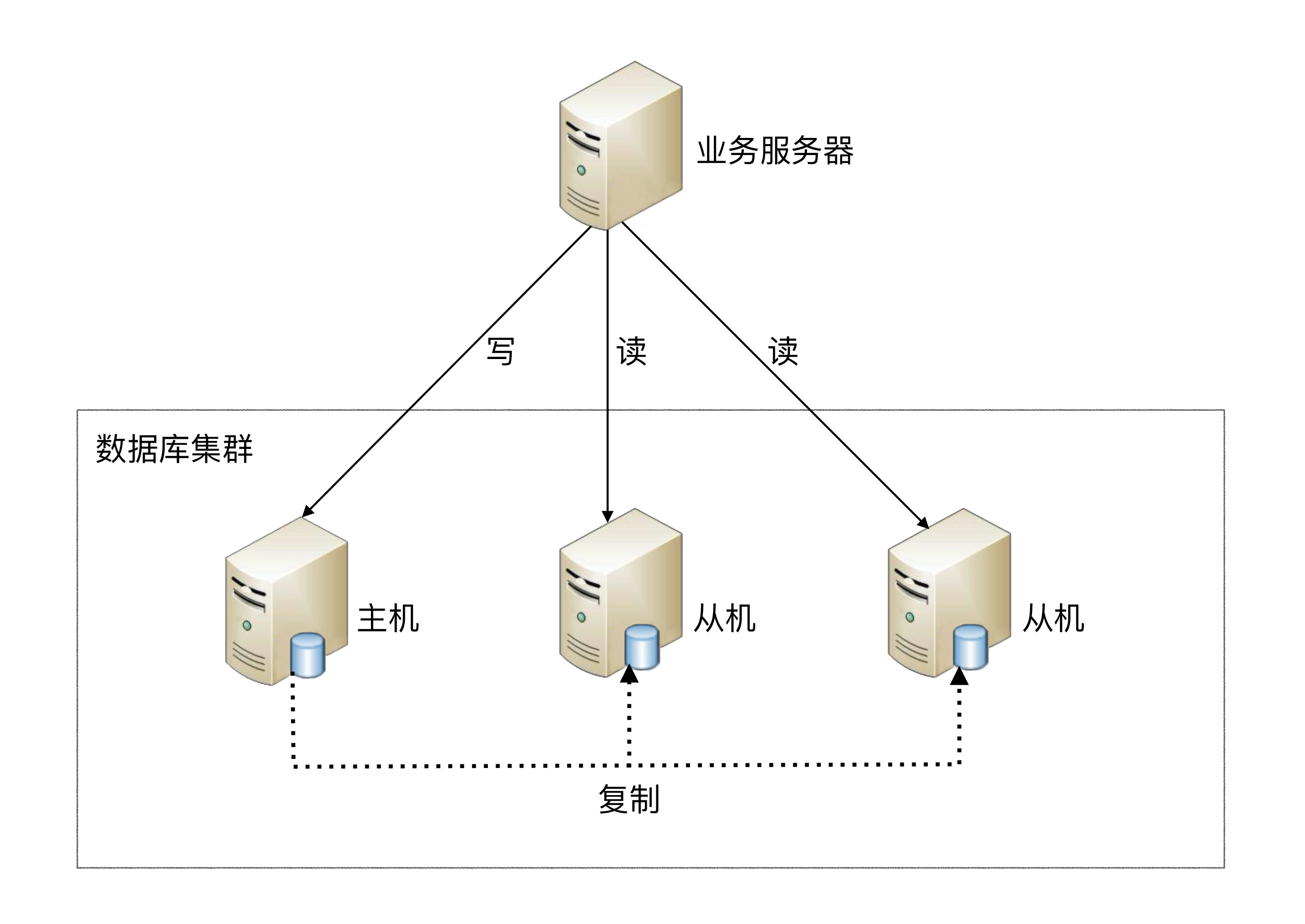
- 读写分离原理: 读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是其基本架构图:
- 读写分离的基本实现:
- 主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
- 读写分离是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。
- 通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
- 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
CAP 理论
- CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer’s theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
- 在一个分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
- C 一致性(Consistency):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果
- A 可用性(Availability):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)
- P 分区容忍性(Partition Tolerance):当出现网络分区后(可能是丢包,也可能是连接中断,还可能是拥塞),系统能够继续“履行职责”
CAP特点
- 在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。
- CP: 在分布式数据库中 , 为了保持
一致性, 当一个节点更新了数据之后, 另外一个节点还没来得及更新,但是此时有服务访问, 该服务必须返回错误相关信息, 但是却违背了 可用性. 因此,只能满足 CP
- AP: 为了保持
可用性, 即使节点还没更新, 当有服务访问时, 服务会返回一个 合理的结果, 但是这个结果可能不是 正确,这就不满足一致性.
一致性: CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点N1 和节点 N2 的数据并不一致(强一致性)。即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性。具有如下特点:
- 基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- 软状态(Soft State):允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
- 最终一致性(Eventual Consistency):系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
数据库分片架构
读写分离的问题:
读写分离分散了数据库读写操作的压力,但没有分散存储压力,为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
数据分片:
将存放在单一数据库中的数据分散地存放至多个数据库或表中,以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
垂直分库
- 将不同的表存储在不同的数据库中
- 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
- 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
垂直分表:
垂直分表适合将表中某些不常用的列,或者是占了大量空间的列拆分出去。
- 拆分一个表中的常用字段和 不常用字段, 这样在查找时, 就只用查找常用的字段,如果需要其他不常用的, 则可以在另外一张表中查找.
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),
-
单表进行切分后,是否将多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。
-
水平分表:单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,可以不拆分到多台数据库服务器,毕竟业务分库也会引入很多复杂性;
-
水平分库:如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就需要将多个表分散在不同的数据库服务器中。
阿里巴巴Java开发手册:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
解决方案
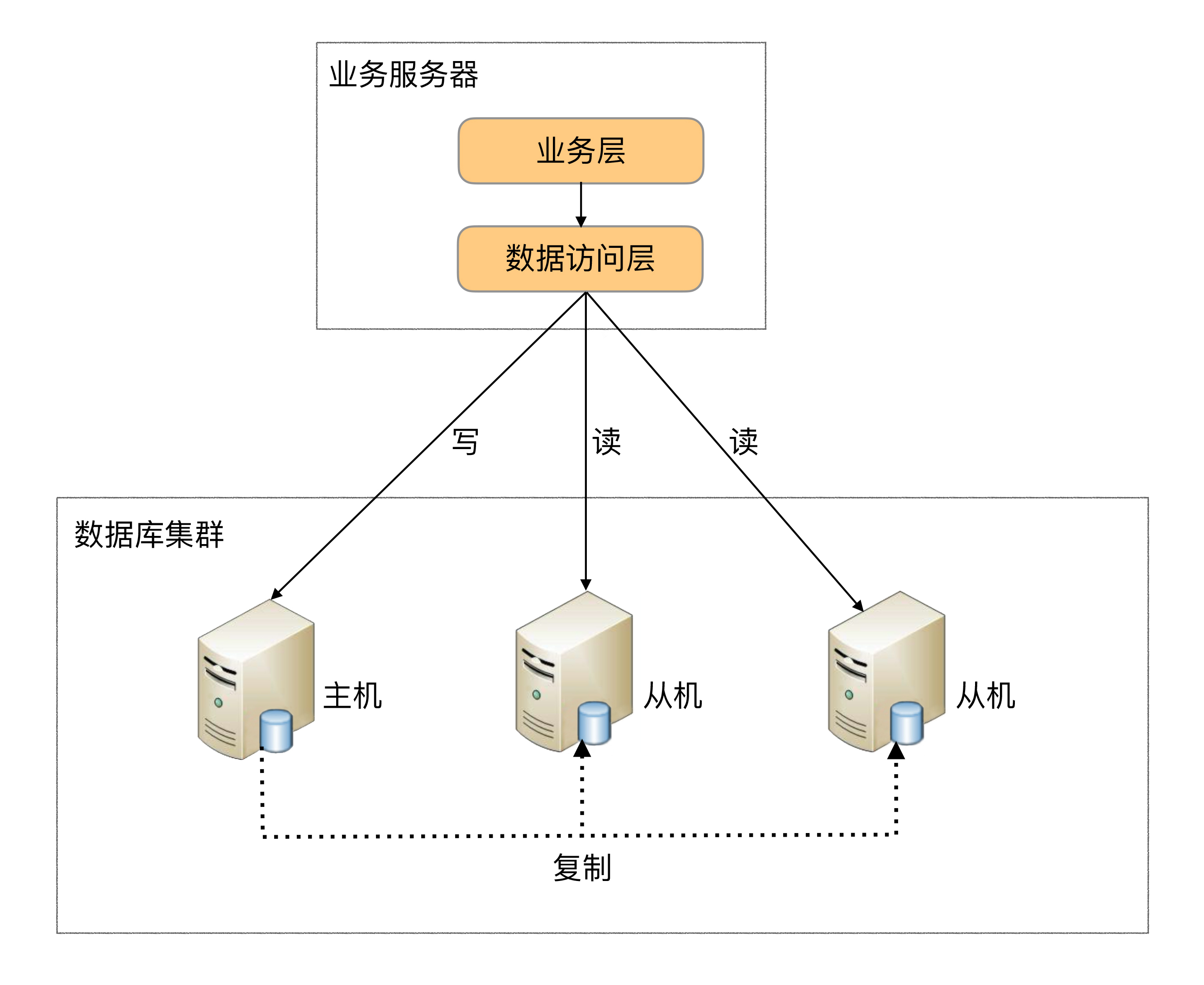
程序代码封装
程序代码封装指在代码中抽象一个数据访问层(或中间层封装),实现读写操作分离和数据库服务器连接的管理。
其基本架构是:以读写分离为例
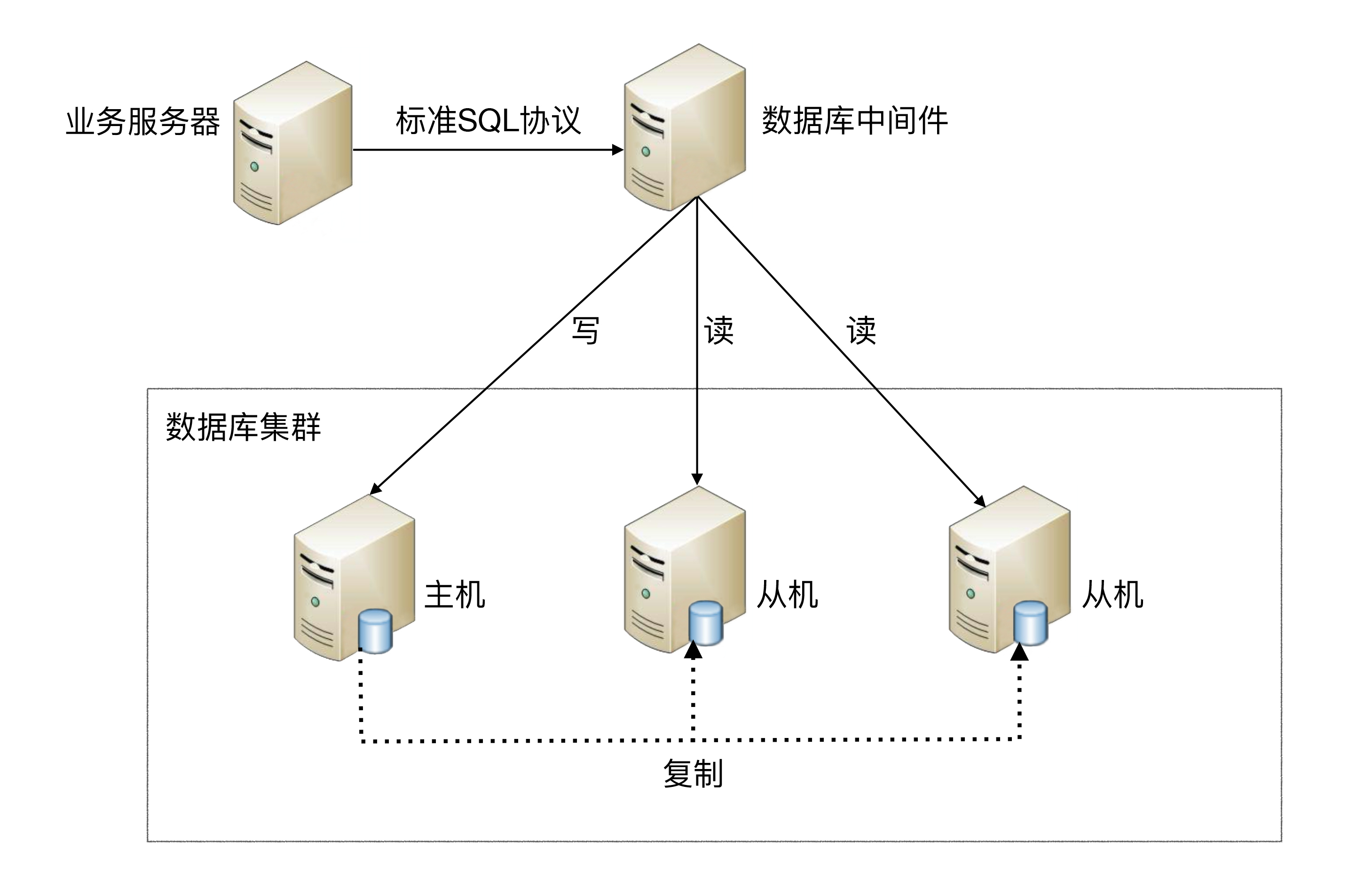
中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。对于业务服务器来说,访问中间件和访问数据库没有区别,在业务服务器看来,中间件就是一个数据库服务器。
基本架构是:以读写分离为例
常用解决方案
MySQL主从同步
MySQL主从同步原理
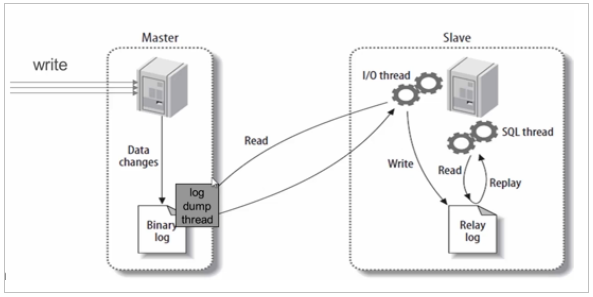
基本原理:
slave会从master读取binlog来进行数据同步
具体步骤:
- step1:master将数据改变记录到二进制日志(binary log)中。
- step2: 当slave上执行 start slave 命令之后,slave会创建一个 IO 线程用来连接master,请求master中的binlog。
- step3:当slave连接master时,master会创建一个 log dump 线程,用于发送 binlog 的内容。在读取 binlog 的内容的操作中,会对主节点上的 binlog 加锁,当读取完成并发送给从服务器后解锁。
- step4:IO 线程接收主节点 binlog dump 进程发来的更新之后,保存到 中继日志(relay log) 中。
- step5:slave的SQL线程,读取relay log日志,并解析成具体操作,从而实现主从操作一致,最终数据一致。
一主多从配置
准备主服务器
1. 开启binlog日志
- binlog: 在主节点中,必须开启, 默认情况下是开启的
- 用于发送增删改的sql记录给从节点进行增量复制.
- 配置文件设置
1
2
3
4
5
6
7
8
9
10
11
12
13
| [mysqld]
server-id=1
binlog_format=STATEMENT
|
-
binlog格式说明:
-
binlog_format=STATEMENT:日志记录的是主机数据库的写指令,性能高,但是now()之类的函数以及获取系统参数的操作会出现主从数据不同步的问题。
-
binlog_format=ROW(默认):日志记录的是主机数据库的写后的数据,批量操作时性能较差,解决now()或者 user()或者 @@hostname 等操作在主从机器上不一致的问题。
-
binlog_format=MIXED:是以上两种level的混合使用,有函数用ROW,没函数用STATEMENT
binlog-ignore-db和binlog-do-db的优先级问题:
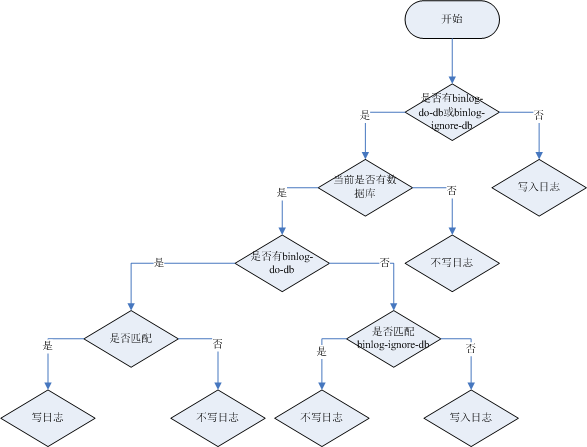
2. 在主机中创建salve用户
1
2
3
4
5
6
7
8
|
CREATE USER 'atguigu_slave'@'%';
ALTER USER 'atguigu_slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE ON *.* TO 'atguigu_slave'@'%';
FLUSH PRIVILEGES;
|
3. 主机中查询master状态
执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
SHOW MASTER STATUS;
记下File和Position的值。执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化。

准备从服务器
1. 编写配置文件
配置主从关系
1
2
3
| CHANGE MASTER TO MASTER_HOST='192.168.100.101', # 主机的ip
MASTER_USER='atguigu_slave',MASTER_PASSWORD='123456', MASTER_PORT=3306, # 主机的账号和端口号
MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=1357; # log_file 的文件名 log的起始位置
|
启动主从同步
分别在两台从机上启动从机的复制功能,执行SQL:
1
2
3
| START SLAVE;
-- 查看状态(不需要分号)
SHOW SLAVE STATUS\G
|
两个关键进程:下面两个参数都是Yes,则说明主从配置成功!
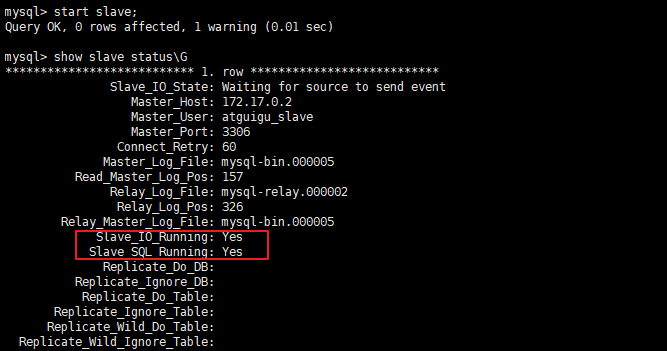
ShardingSphere-JDBC读写分离
添加依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.4.0</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
|
配置shardingsphere
application.yml
1
2
3
4
5
|
spring:
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:shardingsphere.yaml
|
shardingsphere.yaml
模式配置:
1
2
3
4
5
| mode:
type: Standalone
repository:
type: JDBC
|
数据源配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| dataSources:
write_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3306/db_user
username: root
password: 123456
read_ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3307/db_user
username: root
password: 123456
read_ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3308/db_user
username: root
password: 123456
|
读写分离配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1
transactionalReadQueryStrategy: PRIMARY
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
|
读写分离配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1
transactionalReadQueryStrategy: PRIMARY
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
|
输出sql:
负载均衡算法配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
| rules:
- !READWRITE_SPLITTING
loadBalancers:
random:
type: RANDOM
round_robin:
type: ROUND_ROBIN
weight:
type: WEIGHT
props:
read_ds_0: 1
read_ds_1: 2
|
事务测试
transactionalReadQueryStrategy: PRIMARY
事务内读请求的路由策略,可选值:
PRIMARY(路由至主库)
FIXED(同一事务内路由至固定数据源)
DYNAMIC(同一事务内路由至非固定数据源)。默认值:DYNAMIC
ShardingSphere-JDBC垂直分片
- 垂直分库 : 将不同的表存储在不同的数据库中
- 垂直分表 : 一张表分为多张表,结构不同.
垂直分片的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
mode:
type: Standalone
repository:
type: JDBC
dataSources:
user_ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3301/db_user
username: root
password: 123456
order_ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3310/db_order
username: root
password: 123456
order_ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.100.101:3311/db_order
username: root
password: 123456
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: user_ds.t_user
t_order:
actualDataNodes: order_ds_0.t_order0
props:
sql-show: true
//@TableId(type = IdType.AUTO)//依赖数据库的主键自增策略
@TableId(type = IdType.ASSIGN_ID)//分布式id
|
ShardingSphere-JDBC水平分片
-
水平分库:
- 多个数据库实例中:
水平分库是指将同一个数据库的表,按照某种规则(比如根据用户ID或地理区域)分散到不同的数据库实例上。每个数据库实例存储相同的表结构,但表中的数据不同。这样可以减少单个数据库实例的压力,增加系统的吞吐量。
-
水平分表:
- 一个数据库实例中:
水平分表是指将同一个表中的数据,按照某种规则划分成多个物理表,但这些表分布在同一个数据库中,逻辑上依然是一个表。水平分表的目的是减少单表的数据量,降低数据库操作的负担。
水平分库配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
mode:
type: Standalone
repository:
type: JDBC
dataSources:
ds_order_01:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.1.129:3340/db_order_01
username: root
password: 123456
ds_order_02:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.1.129:3341/db_order_01
username: root
password: 123456
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_order_0${1..2}.t_order_01
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: userid_inline
shardingAlgorithms:
userid_inline:
type: INLINE
props:
algorithm-expression: ds_order_0${user_id % 2+1}
props:
sql-show: true
|
水平分表配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
mode:
type: Standalone
repository:
type: JDBC
dataSources:
ds_order_01:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.1.129:3340/db_order_01
username: root
password: 123456
ds_order_02:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://192.168.1.129:3341/db_order_01
username: root
password: 123456
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_order_0${1..2}.t_order_0${1..2}
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: userid_inline
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orderid_inline
shardingAlgorithms:
orderid_inline:
type: INLINE
props:
algorithm-expression: t_order_0${id % 2 + 1}
userid_inline:
type: INLINE
props:
algorithm-expression: ds_order_0${user_id % 2+1}
props:
sql-show: true
|
多表关联
在server-order0、server-order1服务器中分别创建两张订单详情表t_order_item0、t_order_item1
我们希望同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。
那么在t_order_item中我们也需要创建order_id和user_id这两个分片键
- 当两个表存在关联,进行分库分表时,有关联的数据需要在同一个数据库的表中,
- 因此,当对其中一个表进行分库分表时, 另外一个表也需要有相同的分库分表列,且有相同的分库分表策略
